Method
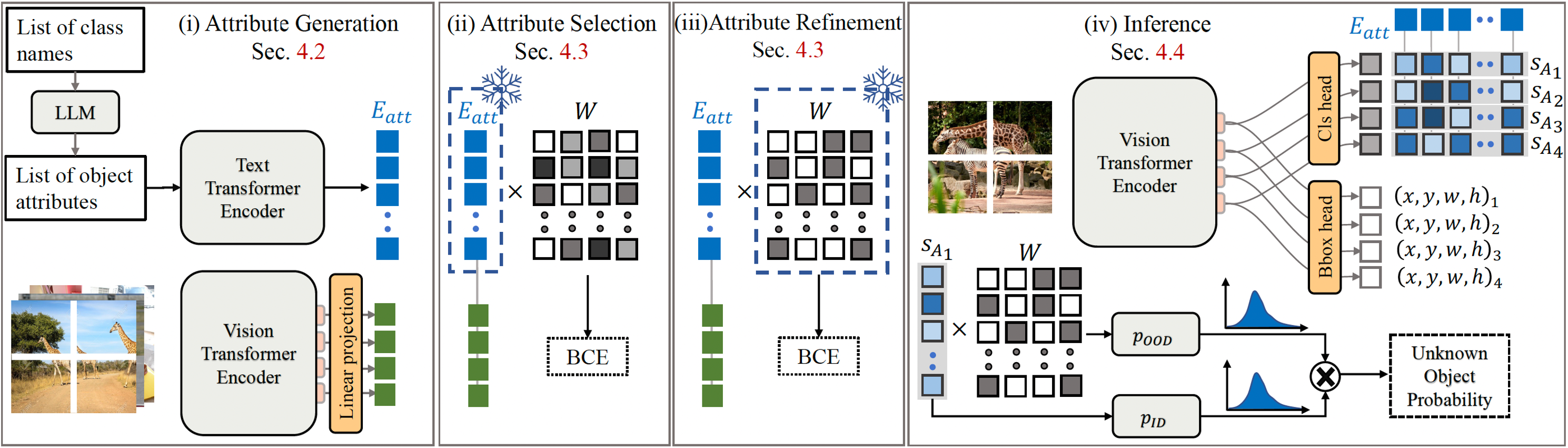
(i) Attributes are generated using an LLM, which is then encoded using FOMO’s Text Transformer Encoder into the Attribute Embedding (E_att). Meanwhile, vision-based object embeddings are derived from (image-based) object exemplars from the models’ Vision Encoder (e^v). (ii) For attribute selection, we update W while freezing E_att using the BCE classification loss, followed by a threshold. (iii) to refine the attributes, we update E_att while freezing W. (iv) An image is fed into the vision encoder during inference, followed by the bounding box and classification heads. The classification head utilizes the pre-computed attribute embeddings to produce the attribute logits. To identify unknown objects, we look for object proposals that are in-distribution (ID) to the attributes but out-of-distribution (OOD) to the known classes. s_A attribute scores between an image and attribute embedding.